1. About Flume
플럼은 인공수로, 용수로 등의 사전적 의미를 가진다. 여러 서비스 제공 서버에 산재해 있는 로그들을 하나의 로그 수집서버로 모으는 역활을 수행해야하는 수집기로서 어울리는 이름이다. 전형적인 Converging Flow 의 구조로 구성되는 Flume은 스트림 지향의 데이터 플로우를 기반으로 하며 지정된 모든 서버로 부터 로그를 수집한 후 하둡 HDFS와 같은 중앙 저장소에 적재하여 분석하는 시스템을 구축해야 할 때 적합하다. Flume은 아래 4가지 사항에 대한 핵심사항을 만족시키도록 설계되었으며 이를 바탕으로 최신 아파치 오픈소스 버전을 제공하고 있다.
- 시스템 신뢰성 (Reliability) - 장애가 발생시 로그의 유실없이 전송할 수 있는 기능
- 시스템 확장성 (Scalability) - Agent의 추가 및 제거가 용이
- 관리 용이성 (Manageability) - 간결한 구조로 관리가 용이
- 기능 확장성 (Extensibility) - 새로은 기능을 쉽게 추가할 수 있음
클라우데라에서 개발하던 0.x 버전을 Flume OG 라고 지칭하며 아파치 오픈소스로 이관된 이후의 1.X 버전을 Flume NG라고 부른다. Flume OG 에서 Agent, Collector, Master로 구분되어지던 아키텍쳐 구조가 Flume NG 에서는 하나의 Agent 로 통합되어 단순해졌으며 이전 버전보다 기능은 줄어들었지만 단순한 구조로 인해 확장성과 자유도가 높아서 훨씬 유연하게 업무에 적용 가능해 졌다. Google 검색을 통해 Flume 관련 정보를 검색하면 아직까지도 Flume OG에 대한 내용이 훨씬 많이 조회되지만 프로젝트를 시작할 당시에 비해 지금은 Flume NG 관련 정보가 많이 확인이 된다.
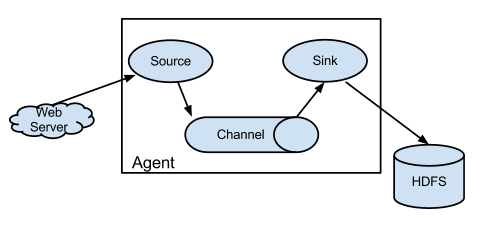
[그림1] Flume NG 기본 아키텍쳐 (출처 : http://flume.apache.org )
Flume NG는 하나의 Agent로 구성되는데 Agent는 내부적으로 source 와 sink 그리고 channel 로 구성된다.
- source - Event를 받아 입력된 정보를 Sink 로 전달한다.
- channel - Source와 Sink의 dependency를 제거하고 장애에 대비하기 위하여 중간 채널을 제공하며 * Source는 channel에 event 정보를 저장하며 sink는 채널로 부터 정보를 전달받아 처리한다.
- sink - 채널로 부터 source 가 전달한 event 정보를 하둡 HDFS에 저장하거나 다음 Tier의 Agent 또는 DB로 전달한다. 지정된 프로토콜의 type에 따른 처리를 진행한다.
2. Flume Converging Flow
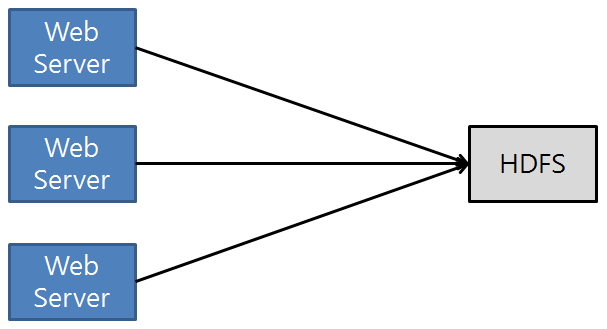
[그림2] HDFS Direct 연동
각 서버의 로그를 수집하기 위하여 HDFS로 직접 연결시 각 서버마다 연동을 위한 복잡한 코드들과 지속적인 관리가 필요하다. 유지보수 비용 측면이나 확장성 관점에 추천할 수 없는 구조이다.
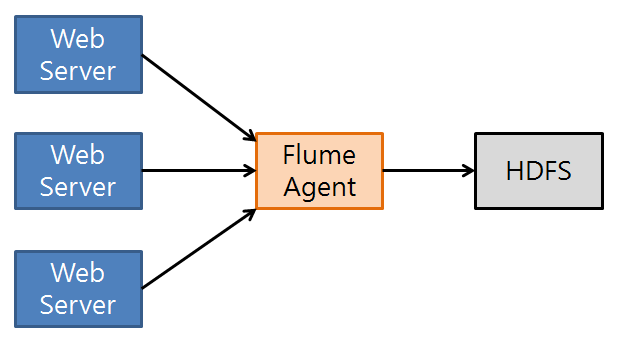
[그림3] Single Flume Agent 연동
로그 수집의 권한을 Flume으로 위임함으로 각 서버들은 고객들에게 기존보다 빠른 서비스를 제공할 수 있다. 하나의 Flume Agent가 로그를 수집함으로써 Flume Agent의 장애 발생시 로그수집이 중단 될 수 있는 문제가 존재한다.
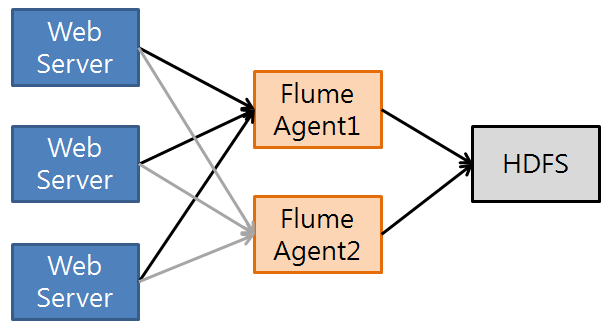
[그림4] Multi Flume Agent 연동
장애 발생시 최소한의 투자비용으로 가용성을 확보 할 수 있다. 장애로 인해 flume Agent가 중지되더라도 백업 agent를 통해 계속 로그 수집을 진행 할 수 있으므로 서비스 지속성을 확보 할 수 있다. 장애 대응을 위한 failover 나 로그 event 정보를 분산하기 위한 load balance 기능등 상황에 맞게 적용하면 된다.
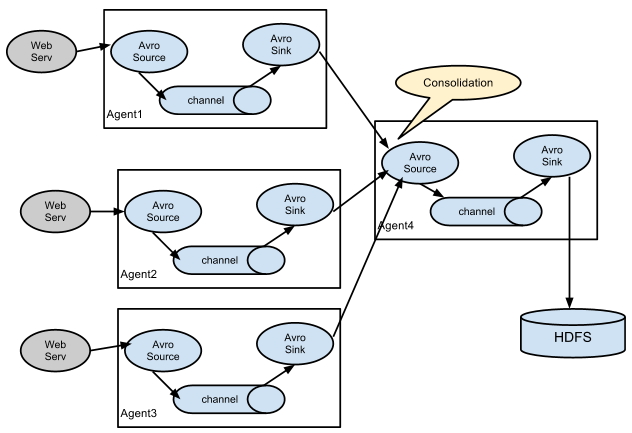
[그림5] 대량 로그를 처리를 위한 일반적인 구조 (출처 : http://flume.apache.org/FlumeUserGuide.html )
100개 이상의 서버로 부터 대량의 로그를 수집할 경우 여러 단계의Tier를 구성하여 로그를 수집한다. 하나의 Flume Agent로 로그가 집중됨으로 인해서 서버 부하 발생 및 처리 지연을 방지하기 위하여 Tier별로 구성하여 처리한다. 현재 진행중인 프로젝트에서는 21개의 서버로 부터 로그를 수집하므로 여러 단위 Tier로 구성하지 않았다. 각 시스템 상황에 맞추어 Flume Agent 의 Tier를 구성할 필요가 있다.
3. Flume Topology Planning
3.1 Tier 수 결정
하나의 Agent collector 는 4~16 개의 Agent를 수용하도록 설계한다.
load balancing 이나 failover 에 대한 요구사항이 없을 경우
- outer tier 의 경우 1:16 비율로 구성
- inner tier 의 경우 1:4 비율로 구성
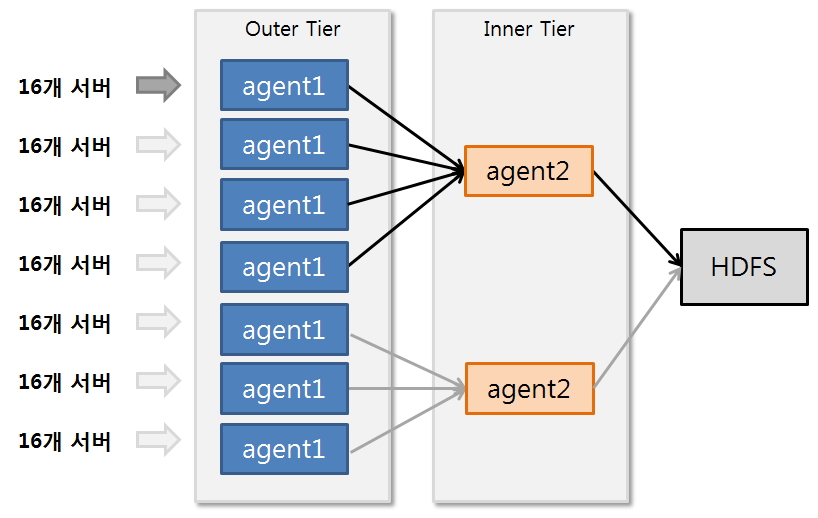
[그림6] Flume Tier 구성 예
예를 들어 100개의 서버로 부터 로그를 수집할 경우 outer tier는 100/16 ~ 100/7 로 Tier 1을 구성한다. inner tier의 경우 7/4 ~ 7/2 로 구성한다. 이렇게 구성할 경우 최종 Tier의 수는 2개에 9개의 agent를 설치하게 된다.
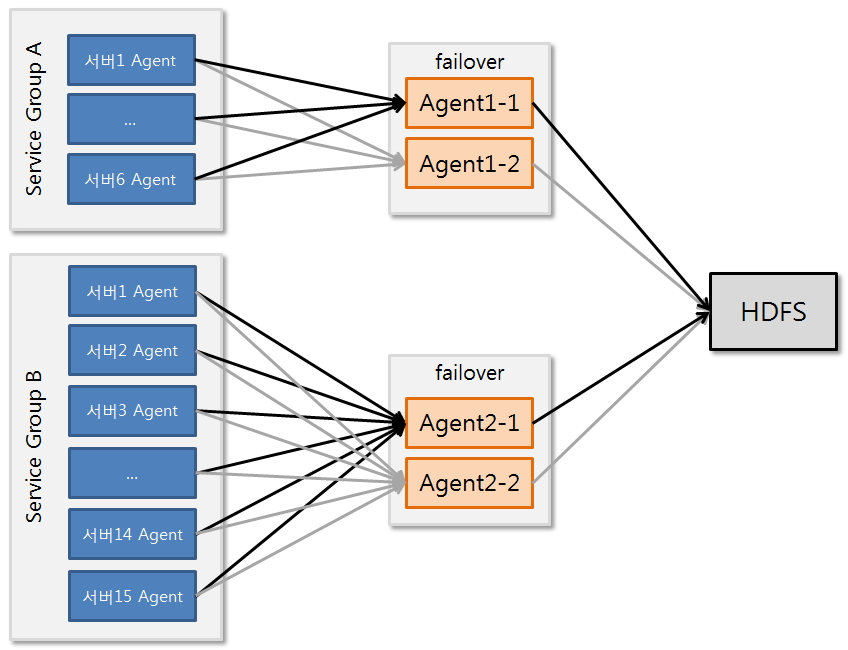
[그림7] A프로젝트의 Tier 구성
현재 진행하는 프로젝트의 경우 21개서버에 각각 agent를 설치하여 Outer Tier의 agent가 하나의 서버만 담당하도록 구성하였으며 이를 1:16의 비율로 하나의 agent가 16개의 agent의 sink 정보를 받도록 처리하였다. 그리고 가용성을 보장하기 위하여 로그를 수집하는 Agent Collector 를 2중으로 failover로 구성하였다. 하나의 inner tier의 허용치를 측정하기 위하여 21개의 outer tier agent를 연결하였으며 허용범위내에서 로그적재를 처리하는 것을 확인 할 수 있었다. 하지만 1:16의 권고 사항과 서버 그룹별로 로그를 분리 수집하기 위하여 agent Collector를 분리하였으며 하둡에 적재하는 파일명으로 구분할 수 있도록 처리하였다.
3.2 Sink Batch Size 결정
batch size가 2500 보다 큰 값이라면 multiple sinks 를 고려해야 한다. event의 발생수치를 기준으로 sink의 batch size를 결정한다. 이전 섹션에서 이야기 했던 것 처럼 16개의 서버로 부터 agent가 로그를 수집할 경우 를 생각해보자. 각 서버별로 초당 100개의 이벤트가 발생한다고 가정하면 Tier 1 의 agent collector의 source는 16개서버 x 100 = 1600개의 event 정보를 받게 된다. 즉 해당 agent collector의 sink는 최소한 1600의 batch size를 가져야 한다는 의미이다. Tier2 의 agent는 1:4 비율에 의해 1600 X 4 = 6400 의 event 정보를 수집하게 된다. batch size가 2500 보다 크므로 3개의 sink로 나누어 2150 batch size를 가지도록 조정한다. sink의 batch size 는 해당 채널의 transactionCapacity보다 같거나 작아야 한다.
3.3 File Channel Capacity 산정
Channel은 memory, file, jdbc , 사용자 정의 채널 등 몇가지 타입을 지원하고 있는데 메모리 채널 보다는 데이터의 유실이 없는 파일 채널을 권장한다. 프로젝트를 진행하면서 메모리 채널에 대한 성능 테스트를 수행했을 때 성능은 사용자 요구치에 만족되지만 안정성 문제로 파일 채널을 결정했다. 일반적으로 가이드에서 File Channel 의 용량산정을 아래와 같이 추정하라고 가이드 한다.
- 시스템이 다운되었을때 몇시간의 DATA를 캐쉬에 보관할 것인가?
(보통 2시간을 권장한다.) - channel.capacity : 초당 event 발생량으로 최종 크기를 산정한다. 시스템 안정성을 보장하기 위하여 1.5배의 예비공간을 확보한다.
(초당 100건 X 60 X 60 X 2 = 720,000 예비공간 720,000 X 1.5 = 1,080,000 최종 1,080,000의 capacity 설정) - event당 byte size를 고려하여 최종 capacity의 물리적인 크기를 계산하여 디스크 예비공간을 확보한다.
A프로젝트의 capacity 계산
A프로젝트의 데이터 발생건수는 평균 450만개(주말 약 600만개, 주중 약500만개) 의 데이터가 발생하며 초당 평균 53건이 발생한다. 권장 계산방식에 따라 2시간의 채널 용량을 계산하면 (53 X 60 X 60 X 2) X 1.5 = 572,400 의 capacity를 설정해야한다.
A프로젝트의 capacity 에 따른 디스크 공간 계산
evnet의 전체 데이터 크기를 계산해 보면 평균 약75G (주말 110G, 평일 70G) 정도이며 시간당 평균 3365471510.15 byte의 정보가 생성된다. capacity 와 동일한 방식으로 계산을 해 보면 (3365471510.15 x 2) X 1.5 = 9.4G 이다. 두시간의 event 를 적재하기 위하여 각 Agent서버 별로 약 9.4G 의 공간을 확보하여야 하며 Agent Collector의 경우 21개 서버로 부터 유입되므로 9.4G X 21 = 197.4G의 디스크 공간이 준비되어야 한다. 평균값으로 capacity와 디스크 예비공간을 계산했지만 최대 발생수치를 고려하여 계산하는 것이 안전할 것이다. 각 프로젝트에서 적절히 판단하여 적용할 필요가 있다.
4. Flume Troubleshooting Guide
이번 섹션에서는 A프로젝트를 진행하면서 경험했던 사항들에 대해 기술 한다. Flume 을 적용하면서 부터 참조 했던 Flume User Guide 는 각 항목에 대하여 설명이 잘 정리되어 있으나 세부적인 설정을 할 때 판단 할 수 있는 기준에 대한 정보가 부족했다. 실제 특정 항목에 의문이 생길 경우 도움을 받을 수 없었으며 대부분 경험에 의해 기능들을 검증할 수 밖에 없었다. 조금만 더 세부적인 설명이 첨가된다면 사용자에게 많은 도움이 될 수 있으리라 생각된다.
4.1 하둡 연계시 유의사항
flume과 하둡 적재시 dfs.datnode.du.reserved 항목은 반드시 선언되어야 한다.
A프로젝트 일정 중간에 1차 오픈을 위해 최종 점검을 하던 중 예상치 못한 문제를 확인할 수 있었다. 프로젝트 초창기 부터 고객사에게 요청했던 하드웨어가 오픈이 한달 앞으로 다가왔음에도 불구하고 아직 준비되지 않았고 하둡 클러스터링을 위한 테스트 서버들도 준비되지 않은 상태였다. 3주가 남은 시점에 겨우 하둡 클러스터링 테스트 환경이 준비되었고 분산모드 테스트 위한 하둡설정과 flume 연동 테스트를 진행하였다. 일정적으로 준비기간이 부족하다 보니 많은 부분에서 테스트가 부족한 상황이 이었다. 하둡 클러스터링을 설정하면서 성능향상을 위하여 hdfs block size 128M , replication 2 값을 지정하였고 당연히 이 설정에 의해 로그가 수집되고 있다고 생각 하고 있었다. 1차 오픈을 일주일을 앞두고 하둡 HDFS에 적재된 로그를 확인하던 중 우리가 정의된 설정과는 달리 block size는 64M , relication은 1의 값으로 로그가 적재되고 있는 것을 발견했다. 다시 한번 하둡의 설정값들을 확인하였지만 아무런 설정상의 문제점을 찾을 수 없었다. 오류 상황에 대한 시뮬레이션 점검 결과 서버에 텔넷으로 접속하여 command 상에서 하둡 명령어를 통해 직접 로그를 HDFS에 등록할 경우 설정한 수치대로 로그가 정상적으로 적재되는 것을 확인 할 수 있었으며 Flume Agent를 통해서 적재되는 로그만 현재 설정값이 아닌 하둡의 default Value로만 적재되는 문제가 있다는 것을 확인 할 수 있었다.
구글링을 통해 2013년 4월 해당 버그를 해결하기 위한 flume 임시 patch가 user에 의해 등록되었음을 확인하였다.
(https://issues.apache.org/jira/browse/FLUME-2003)
하지만 해당 임시 패치는 7월 flume1.4.0 정식 릴리즈에서 제외 되었다.
(https://issues.apache.org/jira/browse/FLUME-2027)
하둡서버의 버그로 인한 것이므로 flume에서 임시 패치 내용을 반영하지 않는 것으로 결정 되었다.
(https://issues.apache.org/jira/browse/HADOOP-8014)
하둡버전을 1.1.0 이상 사용하면 해결된다는 코멘트를 발견 했지만 현재 사용하는 하둡 1.2.1에서도 이러한 현상이 확인되는 것으로 보아 아직 일부 결함이 존재하는 것으로 생각된다. 해당 문제에 대한 해결방법을 찾지 못하다가 data node의 작업 공간을 확보하기 위하여 디스크 예비공간을 지정하는 dfs.datnode.du.reserved 항목을 hdfs-site.xml에 선언을 추가하면서 해결의 실마리를 얻게 되었다.
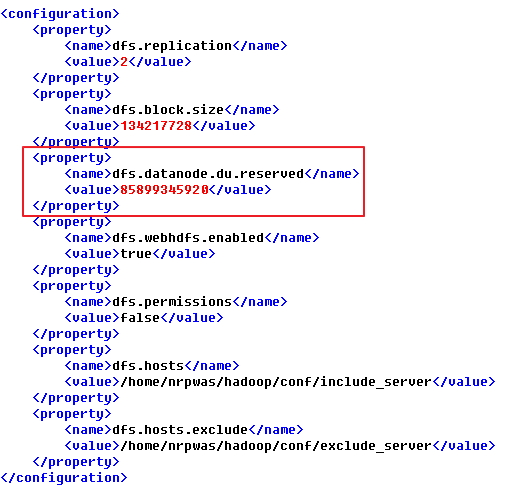
[그림8] 하둡 hdfs-site.xml 설정
이 설정이 추가된 이후 부터 적재되는 하둡의 로그가 처음 의도한 바대로 정상적인 설정값이 반영되기 시작했다. 대부분 프로젝트에서는 reserved 값을 처음부터 설정하고 시작하는 경우가 많아 이러한 오류를 확인하지 못하는게 아닌가 생각된다.
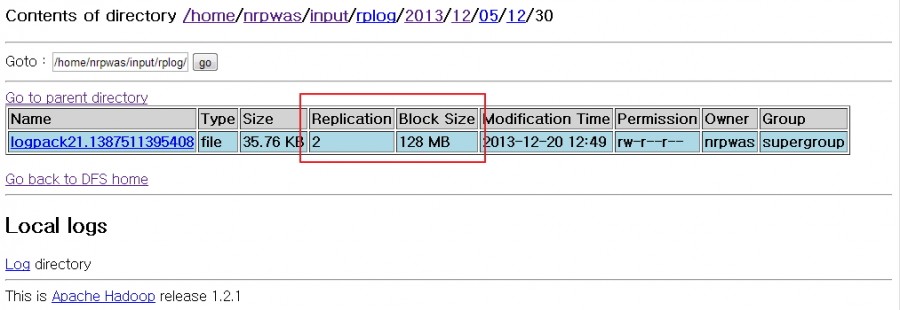
[그림9] 정상적으로 적재되는 로그
4.2 Physical Server vs Virtual Server
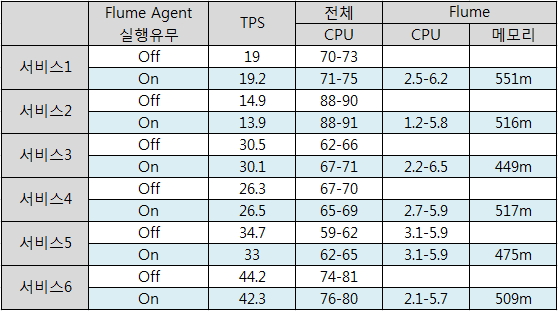
[그림10] Physical Server에서의 시스템 사용량 측정
스트레스 테스트 Application : JMeter
테스트 스레드 수 : 500개
테스트 방법 : 1부터 순차적으로 500개까지 증가
위의 표는 특정 서비스가 수행되고 있는 동안에 Flume Agent를 기동하여 로그를 수집할때와 flume Agent가 멈춰 있을때의 시스템 자원 사용량을 측정한 것이다. 업무 특성상 binary 로그파일이 발생하며 Flume Agent는 해당 파일을 parsing 하여 text로 변환하여 agent collector로 전달한다. A프로젝트의 서비스 환경에서 대략 Flume Agent를 기동시 CPU 사용율이 평균 2 ~ 5% 증가하는 것을 확인할 수 있다. 테스트 결과 대량의 트래픽이 발생하는 스트레스 테스트 수행시점의 CPU 사용율은 허용가능 범위로 판단되어 운영서버에 적용을 하게 되었다. 운영서버에서 테스트 결과 테스트 서버와는 전혀 다른 결과가 나타 났다. CPU 사용율은 10 ~ 20% 범위로 늘어 났으며 다행히 메모리 사용율은 테스트 서버의 결과와 크게 차이가 나지 않았다. CPU 사용율이 차이가 나는 원인은 운영서버는 가상화 서버로 구성되어 있는 시스템 장비의 문제로 확신 하였다. 실제 스트레스 테스트를 진행했던 B 서비스 시스템을 개발할 당시 해당 업무에 특정 이미지 resource를 읽어 DATA를 가공한 다음 Client에게 제공하는 기능이 포함되어 있었는데 Runtime시점에 이미지를 read 할 경우 TPS가 저하되는 현상을 경험 할 수 있었고 이는 가상화 서버에서만 나타나는 문제로 확인되었다. TPS 저하를 해결하기 위하여 이미지 resource를 WAS가 start 될 때 캐싱처리를 하였고 해당 시스템으로 부터 원하는 TPS의 성능을 얻을 수 있었다. Flume Agent가 가상화 서버로 구성된 업무 시스템 하에서 가동되고 있으며 바이너리 로그 파일을 읽어 Text로 변환한 다음 다시 FileChannel 에 기록는 과정을 거치게 되니 많은 파일 I/O를 수반하게 되고 이로 인해 CPU 증가를 경험할 수 있었던 것이었다.
[주의]
가상화 서버에서는 file에 대한 I/O 처리가 물리서버에 비해 현저하게 떨어지며 CPU 사용율이 증가하는 원인이 됨. Flume Agent 적용시 이에 대한 고려가 필요함. 대량의 파일 I/O 처리가 필요한 장비에서는 가상화 서버 도입여부를 신중히 결정해야 함
4.3 Flume Failover priority
서버 장애 발생시 가용성을 확보하기 위하여 failover 기능을 도입하게 된다. flume 에서 failover를 적용하기 위하여 master 와 slave agent collector 를 각각 sink 설정하고 failover group으로 묶는다. 이때 우선순위를 지정하는 것이 failover priority 이다. 우리는 agentMainSink와 대응되는 Agent Collector 가 Master 로 동작하기를 원했으나 반대로 Slave Agent Collector 가 Master로 동작하는 것을 확인할 수 있었다.

[그림11] 의도한 바와 다르게 동작하는 failover priority
즉 priority의 수가 작은 것이 Master로 동작한다고 생각하였으나 반대로 숫자의 값이 큰 sink가 Master로 동작하는것이었다. Flume User Guide에 이러한 동작 방식에 대한 언급이 있었더라면 테스트 비용을 줄일 수 있었을텐데 하는 아쉬움이 있다.

[그림12] 의도한 바와 동일하게 동작하는 failover priority
5. 마무리
flume만이 다양한 비즈니스 환경의 로그들을 수집하는 대안이 될수는 없다. flume 이외에도 다양한 오픈소스들이 제안되고 있으며 flume의 자체 기능도 아직은 부족한점이 많이존재한다. 하지만 java 언어로 개발된 flume의 특성으로 인해 무한한 확장 가능성과 고객의 요구사항 및 운영환경의 제약을 자유롭게 풀어나갈수 있는 수단을 제공한다는 것에 추가 점수를 부여할 수 있을 것이다. 우리가 진행한 A프로젝트에서도 로그의 생성방식이 기존의 WAS 방식과 상이하기에 로그를 수집하여 처리하는 부분은 쉽게 새로 재정의하여 구현하여 사용 할 수 있었다. 간결한 아키텍쳐를 제공함으로서 유지보수성과 확장성만으로도 충분히 flume의 사용을 고려해 볼수 있지 않을까 생각한다.
[참조]
Flume User Guide
http://flume.apache.org/FlumeUserGuide.html
how-to-do-apache-flume-performance-tuning-part-1
http://blog.cloudera.com/blog/2013/01/how-to-do-apache-flume-performance-tuning-part-1
"Planning and Deploying Apache Flume" ApacheCon NA 2013,Portland, Oregon,February 26th – 28th, 2013 ApacheCon NA 2013
Flume & Hadoop Issue Item
https://issues.apache.org/jira/browse/FLUME-2003
https://issues.apache.org/jira/browse/FLUME-2027
https://issues.apache.org/jira/browse/HADOOP-8014

