캐시(Cache)는 미리 만들어진 데이터를 임시로 저장하는 공간입니다. 하드웨어(CPU, 메모리, 디스크 등)부터 운영체제, 응용프로그램에 이르기 까지 다양한 IT 분야에서 캐시 매커니즘을 이용하여 한정된 자원을 효율적으로 관리하고, 성능향상을 목적으로 사용하고 있습니다.
웹 애플리케이션의 Long Tail
일반적으로 웹 애플리케이션이 제공하는 기능의 20%가 80%의 자원을 소비하고 있습니다. 그리고 자주 사용하는 데이터는 그 다음에 또 사용될 확률이 매우 높습니다. 따라서 집중적으로 사용되는 20%에 캐시 매커니즘을 도입하면 전체적인 시스템의 성능 향상과 효율적인 자원 사용을 가능하게 합니다.

[참고]일반적인 웹 애플리케이션의 재사용 및 공유 포인트
캐시와 관련된 좋은 글이 있어 내용을 참고하였습니다. http://greatkim91.tistory.com/116
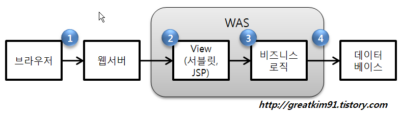
- HTTP 캐싱(304 Not Modified)
- 페이지 요청결과(HTML, XML, JSON…) 재사용
- 서버쪽 연산결과에 대한 재사용
- DB쿼리 결과 재사용, iBatis나 Hibernate 프레임워크의 지원
분산 캐시 아키텍처
일반적으로 상용 서비스를 제공할 때에는 단일 서버(1 JVM)로 시스템을 구성하는 경우는 거의 없을 것입니다. 서버의 부하를 분산시키기 위해 앞에 L4스위치와 같은 장치를 두고 여러대의 서버를 로드 밸런싱 하기도 하고, ADMIN 웹은 따로 분리되기도 하며, 업무별로 서버들이 분리되기도 합니다. 이와 같이 여러 서버(물리적으로 붙어 있던 떨어져 있던...)들이 협업을 통해 서비스를 제공하게 됩니다.
물론 각 서버마다 저마다의 캐시를 가지고 동작하도록 구현할 수도 있습니다. 하지만 여러 서버에서 캐싱되는 데이터가 완전히 동일하고, 실시간적으로 일관성(Consistency)을 보장해야 한다면 여러 서버에 있는 캐시들이 제각각인 것 보다는 모두 동일한 캐시 데이터를 바라보는 것이 자원의 활용이나 소스코드 구현 측면에서 훨씬 효과적일 것입니다.
그래서 필요한 솔루션이 분산 캐시입니다.
분산 환경에서 캐시 공유를 통해 다른 JVM의 애플리케이션에서도 캐시 데이터를 공유할 수 있습니다. 캐싱된 데이터를 여러 시스템에서 활용할 수 있어 퍼포먼스 향상에 도움이 되고 효율적으로 자원을 관리하게 됩니다.
분산 캐시는 다음과 같이 크게 두가지로 방식으로 구분할 수 있습니다.
Hub and Spoke 분산 캐시 아키텍처
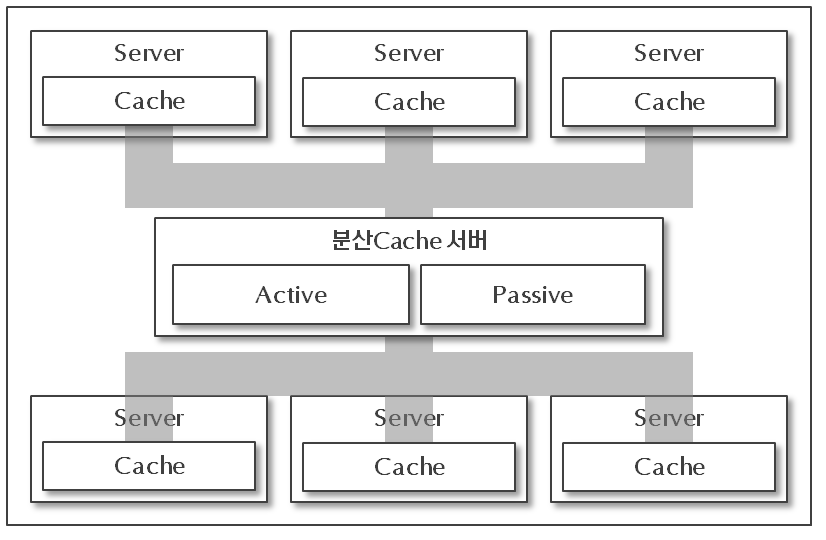
- 분산 캐시를 위하여 중앙에 각 캐시 노드(node)를 제어하는 분산 캐시 서버가 존재함
- 각 캐시 노드 제어를 중앙에서 담당하며 클러스터링을 위해 중앙서버를 통하게 됨
- 각 캐시 노드 들은 내용의 변경을 알리기 위해 중앙 서버에 통지하고 서버는 각 캐시 노드에 변경 내용을 전달하는 방식으로 동작
Replication, Invalidation 분산캐시 아키텍처
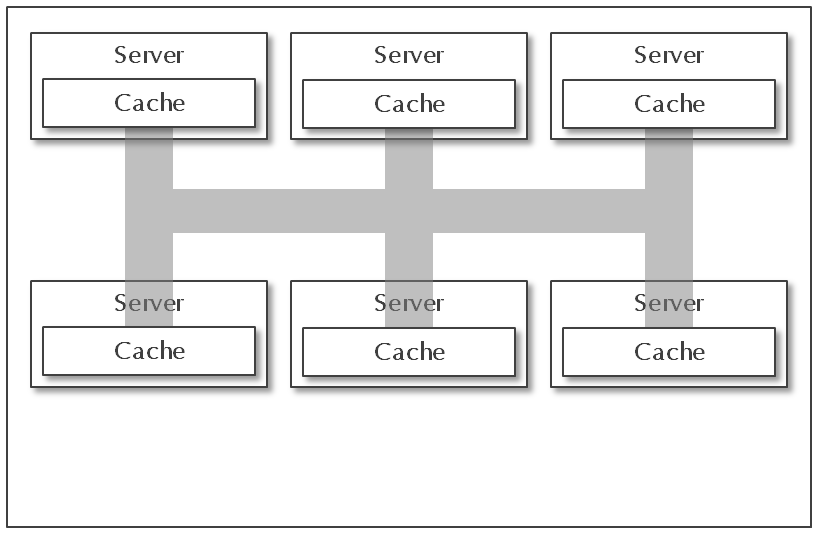
- 각 캐시 인스턴스들 간의 자체적으로 클러스터링 하는 구조
- 한 노드에서 변경이 발생하면 직접 모든 노드에 변경을 알리는 방식으로 동작함
- 노드가 증가할 수록 각 캐시 노드들의 부하가 증가하는 형태임
분산 캐시 솔루션 비교
아래 그림은 프로젝트에 분산 캐시를 도입하기 위해 대표적인 자바 캐시 소프트웨어를 비교한 자료 입니다.(2011년에 작성한 자료이기도 하고 여러 사이트를 검색해서 조사했기 때문에 내용이 잘못되었을 수도 있으니 양해 바랍니다.)
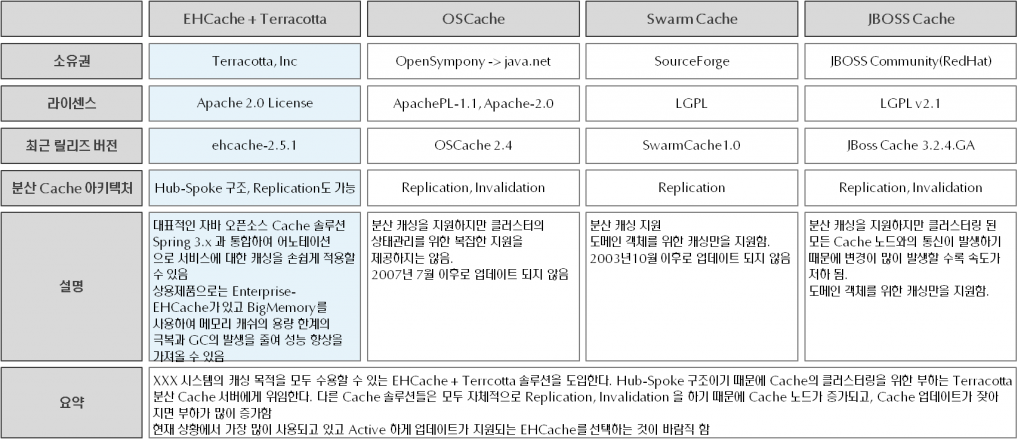
프로젝트에서는 EhCache + Terracotta 조합 으로 분산 캐시를 도입하도록 결정하였습니다.
EhCache
EhCache는 대표적인 자바 오픈소스 캐시 솔루션입니다. 장점들을 나열하자면 쉽고, 빠르고, 확장이 용이하고, 유연하고, 자바 캐시 표준(JSR107)의 구현체이고, 분산 환경에서 사용하기 좋고, 하이버네이트 L2캐시, 웹 페이지 캐싱 등 많은 기능을 지원하고 있습니다. 자세한 내용은 http://ehcache.org/about/features 참조
사용하는 방법은 아주 쉽습니다.
자바 클래스 패스에 캐시 설정파일(ehcache.xml)을 위치하고 애플리케이션에서 사용 할 캐시와 관련된 설정을 합니다.(ehcache.xml 설정파일 이름은 변경 가능합니다.)
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false" monitoring="autodetect" dynamicConfig="true">
<diskStore path="java.io.tmpdir" />
<defaultCache maxEntriesLocalHeap="10000" eternal="false"
timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="true"
maxElementsOnDisk="10000000" diskPersistent="false"
diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU" />
<cache name="simpleCache" maxElementsInMemory="1000" eternal="false"
overflowToDisk="false" memoryStoreEvictionPolicy="LRU">
</cache>
</ehcache>
자바 소스코드에서는 다음과 같이 캐시 매니저 객체를 생성한 후
CacheManager cacheManager = CacheManager.create();
캐시가 필요한 곳에서 ehcache.xml 파일에서 설정한 캐시를 이름(위의 예제에서는 simpleCache)으로 가져와서 put, get, remove등을 수행합니다.
Cache cache = cacheManager.getCache("simpleCache");
...
cache.put(cacheElement);
cache.get(key);
cache.remove(key);
또한 아직 시도해보지는 않았지만 ehcache-spring-annotation 을 사용해서 spring프레임워크와 통합하면 메소드 레벨의 어노테이션으로 캐시를 설정할 수 있다고 하니 캐시에 입력, 삭제하는 행위를 위와 같이 구현하지 않고 사용할 수 있습니다. 유용하게 활용할 수 있을듯 합니다. https://code.google.com/p/ehcache-spring-annotations/ 참조
@Cacheable(cacheName="simpleCache")
public String getSomething(String arg)
{
// 캐시에 값이 존재하면 여기는 수행되지 않습니다.
return ...;
}
@TriggersRemove(cacheName="simpleCache")
public void updateSomething(String arg)
{
...
}
여기까지는 일반적인 ehcache의 사용방법입니다.
Terracotta Server Array
Terracotta는 각 캐시 노드들의 Hub 역할을 하는 분산 캐시 서버입니다. Ehcache+Terracotta의 조합으로 여러 캐시 노드의 동기화를 지원하고 Hub-Spoke 구조이기 때문에 캐시의 동기화를 위한 부하는 Terracotta 분산캐시 서버에 위임하게 됩니다. Terracotta Server는 여러대로 이중화 구성이 가능하며(그래서 Server Array라고 부르는 듯) Active-Passive 모드로 서비스를 하고, 장애발생 시 자동으로 Fault Tolerance 기능을 제공합니다.
저희는 오픈소스버전을 사용 했습니다. 오픈소스와 상용버전의 차이는 BigMemory(off-heap)의 사용가능여부와 기술지원 정도?로 파악됩니다. http://terracotta.org/downloads/open-source/catalog 사이트에서 다운받아 서버 두대에 설치(설치 및 구성 방법은 사이트의 도큐먼트 참조)하였고 Active-Passive 모드로 구성했습니다.
EhCache를 Terracotta Server Array와 함께 분산 캐시로 활용하기
Terracotta Server Array가 설치 되었고 실행중이면 EhCache를 Terracotta Server Array로 연결하는 방법은 매우 간단합니다.
위의 ehcache.xml 파일에 terracotta cluster 관련 설정만 추가하면 해당 캐시가 분산 캐시서버와 동기화 됩니다.
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false" monitoring="autodetect" dynamicConfig="true">
<diskStore path="java.io.tmpdir" />
<terracottaConfig url="xxx.xxx.xxx.22:9510, xxx.xxx.xxx.24:9510" rejoin="true"/>
<defaultCache maxEntriesLocalHeap="10000" eternal="false"
timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="true"
maxElementsOnDisk="10000000" diskPersistent="false"
diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU" />
<cache name="simpleCache" maxElementsInMemory="1000" eternal="false"
overflowToDisk="false" memoryStoreEvictionPolicy="LRU">
<terracotta clustered="true" consistency="strong">
<nonstop immediateTimeout="true">
<timeoutBehavior type="localReads" />
</nonstop>
</terracotta>
</cache>
</ehcache>
자바 소스코드상의 변화는 없습니다. 설정의 추가만으로 해당 캐시는 분산 캐시로 동작하며 위와 같이 terracotta cluster 설정이 되어있는 다른 캐시 노드(다른 서버)들도 함께 동기화 될 것입니다.
[참고]Terracotta 캐시서버 모니터링 도구 지원
Terracotta 서버는 JMX 모니터링을 지원하며 제공되는 클라이언트를 제공하기 때문에 현재 캐시서버의 상태(메모리, 접속 클라이언트, 캐시 아이템 등)를 들여다 볼 수 있고, 캐시 아이템을 런타임(Runtime)에 삭제할 수도 있습니다.
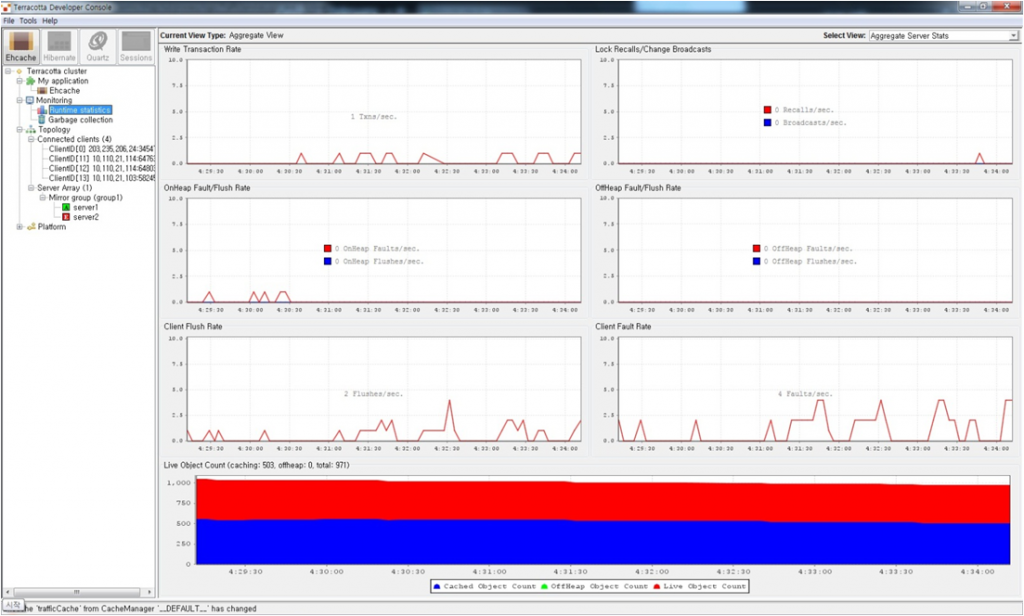
분산 캐시 활용 사례
아래 그림은 최근에 진행했던 프로젝트의 서비스 구독(Subscription) 및 접근제어와 관련된 간략한 도메인 모델입니다.
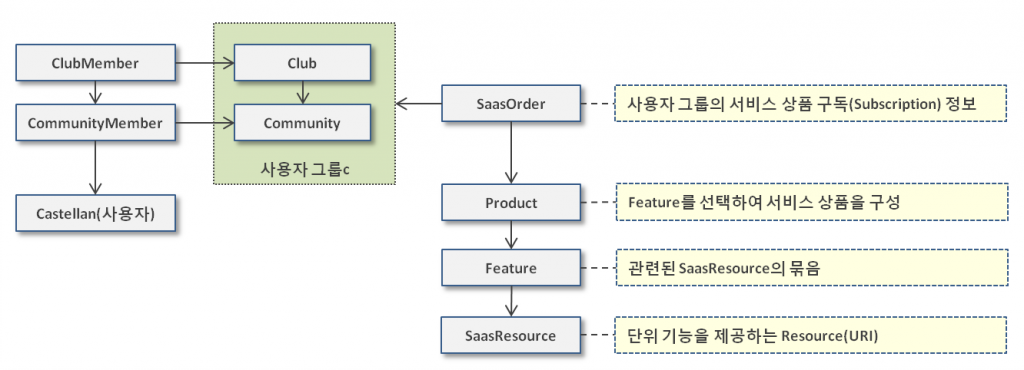
서비스 요청이 발생하게 되면 플랫폼에서는 비즈니스 로직에 진입하기 전에 가로채어(Intercept) 해당 사용자의 서비스 접근 가능 여부를 판단합니다. 해당 사용자 그룹의 구독(Subscription) 정보, 구독 정보가 가지고 있는 상품, 상품에 속한 Feature, Feature에 속한 Resource를 순차적으로 조회해서 요청한 서비스 사용가능 여부를 판단하여 수행합니다.(사용 불가하면 예외를 발생하며 접근 불가 메시지를 함께 전달)
분당 서비스 요청 건수가 수천~수만건 발생하고 있는데 서비스 구독 정보를 매번 DB에서 가져오는 것은 시스템의 부하를 많이 줄 뿐더러 자주 변경되는 데이터가 아니기 때문에 매우 비효율적일 것입니다. 그래서 다음과 같이 위의 정보들을 위해 분산 캐시를 활용 하도록 결정하였습니다.
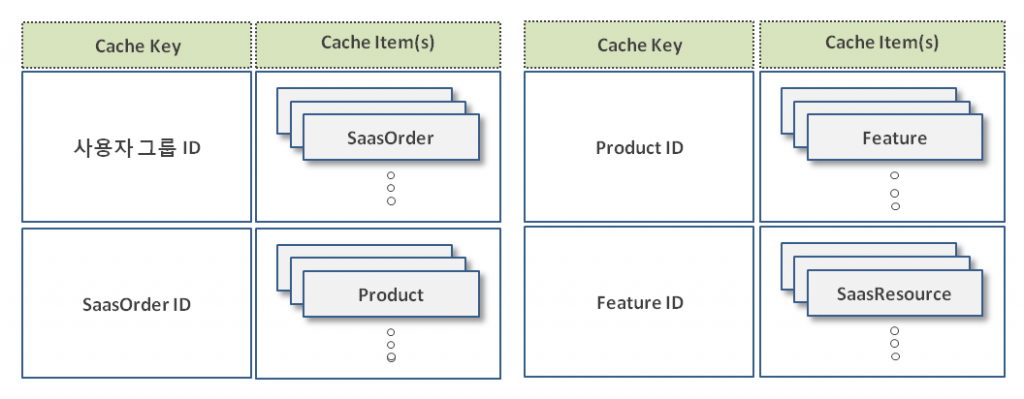
이처럼 캐시 아이템을 구성하였기 때문에 서비스 구독 정보를 가져오기 위한 자원낭비(DB연산 및 네트워크 자원 소모)를 극단적으로 줄일 수 있었고, 분당 수천~수만건의 사용자 접근제어 정보를 처리하는데 문제가 없었습니다. 또한 여러 서버가 설치된 분산 환경이기 때문에 여러대의 접근제어 서버에서도 동일한 캐시 아이템을 효율적으로 사용, 관리할 수 있었습니다.
마무리
참고로 실제 프로젝트에서 분산 캐시를 사용하다보니 가끔씩 Terracotta 캐시 서버가 죽는 현상이 있었습니다. 원인을 파악해 보니 캐시 아이템의 사이즈가 50M가 넘는 것들(여러 이미지 파일을 묶어 압축)을 캐시에 담아서 여러 노드에서 공유해서 사용하고 있었습니다. 이를 Terracotta 캐시서버가 여러 노드에 동기화하는 중 OOM이 발생하였습니다. 그래서 프로젝트에서는 다음과 같은 제약 조건을 두었습니다.
- 하나의 캐시 아이템 사이즈는 512K를 넘지 않아야 한다.
- 각 업무별 캐시 용량(아이템 크기 * 갯수)은 200MB를 넘지 않아야 한다.
정확한 임계치는 아니고 여러 변수들이 존재 하겠지만 대략적으로 테스트 해보니 512K 미만일 때에는 분산 환경에서 여러 노드의 캐시 아이템들이 100ms 이내로 동기화가 이루어 지는 것을 확인 했습니다. 그리고 더이상 Terracotta가 다운되는 현상은 발생되지 않았습니다.
우리가 만드는 애플리케이션에는 캐시를 활용할 수 있는 다양한 지점이 있습니다. 캐시는 잘 활용하면 시스템 성능을 대폭 향상시킬 수 있는 좋은 기술 이고, 위와 같이 분산 환경에서 활용하면 성능 향상 뿐만아니라 여러 캐시 노드들 간의 데이터 공유의 목적으로도 활용할 수 있습니다. 하지만 과도한 사용은 구조를 복잡하게 만들기 때문에 필요한 곳을 잘 선정해서 사용해야 겠습니다.
EhCache + Terracotta Server Array 는 프로젝트에서 사용해보니 괜찮은 자바 분산 캐시 솔루션인것 같습니다. 위에서 보신바와 같이 적용하는데 크게 어려움이 없으며 안정적으로 잘 운영되고 있습니다. 다만 깊게 들어가면 많은 부분들을 조절해가며 분산 캐시 동작 방식을 튜닝할 수 있으니 자세히 알고 적용해야 겠습니다.